如何自己制作Lora模型去绘画某个人物或者特定的风格呢,下面以制作蔡徐坤的人物Lora模型为例,教大家怎么去制作自己的Lora模型。
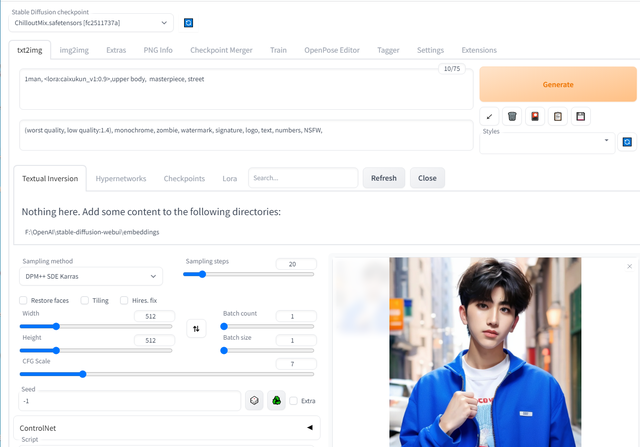
使用自己做的LoRA绘制出蔡徐坤图片

使用自己做的LoRA绘制蔡徐坤图片
在开始制作之前,我们先回顾下什么LoRA模型,了解基本原理我们选参数时就不会手足无措。
LoRA: 全名为Low-Rank Adaptation of Large Language Models(大语言模型的低阶适配器),简单来说就是大语言模型的微调小模型,在Checkpoint的大模型的下通过这个小模型可以进行微调。模型存放位置在models\LoRA下。
可以看出LoRA是在某个Stable Diffusion大模型下训练生成的一个小模型,用于微调大模型。LoRA可以调整人物,也可以调整风格。
例如下图是加载了蒂法的LoRA,这是人物LoRA(tifaMeenow_tifaV2.safetensors)

加载了人物LoRA
还有改变画面风格的LoRA,例如水彩风格(Colorwater_v4.safetensors沁彩)

加载了水彩风格LoRA
目前进行LoRA模型训练只要8G显存就可以了(笔者就是使用1080/8g写的教程,为了适应更多人的需求,实际工作使用的3060/12G),个人推荐进行训练用3060/12G显卡这样避免显存不够的错误。训练使用的程序框架是kohya_ss。kohya_ss是一个All in One的程序包(傻瓜包)整合了训练用的所有软件,还有图形用户界面。所有软件都是在它自己的运行环境里运行,不会干扰其他的程序软件。安装kohya_ss非常简单,唯一要求是可以科学上网。
kohya_ss的地址
https://github.com/bmaltais/kohya_ss
本次例子使用真人大模型ChilloutMix.safetensors,来生成蔡徐坤的Lora,显卡使用1080/8g进行训练。
整个训练过程分为三步:
- kohya_ss训练环境搭建
- 图片处理和标注
- 训练并生成LoRA模型,并用它来进行AI绘图
下面开始依次进行说明:
一. kohya_ss环境搭建,主要按照它官方的教程来,我只说明下需要注意的地方。地址是:(如果出现问题,多半是没有科学上网)
https://github.com/bmaltais/kohya_ss
依赖库安装
- 安装 Python 3.10,将 Python 加入 'PATH' 环境变量这项打勾
- 安装 Git
- 安装Visual Studio 2015, 2017, 2019, and 2022 redistributable
Visual Studio 2015, 2017, 2019, and 2022 redistributable的地址:
https://aka.ms/vs/17/release/vc_redist.x64.exe
进行AI绘图的人前两项安装已经装过了,所以直接跳过,只需要装第三项。
装好之后需要更改powerShell的权限,用管理员运行里执行
运行里输入PowerShell
输入 :Set-ExecutionPolicy Unrestricted
然后输入Y,见下图:
更改权限
然后关闭它就可以了。如果你windows是管理员运行的这步可以省略。
然后再开一个窗口,开全局科学上网,依次一行一行复制以下命令,一个字都不要改
git clone https://github.com/bmaltais/kohya_ss.gitcd kohya_sspython -m venv venv.\venv\Scripts\activatepip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 --extra-index-url https://download.pytorch.org/whl/cu116pip install --use-pep517 --upgrade -r requirements.txtpip install -U -I --no-deps https://github.com/C43H66N12O12S2/stable-diffusion-webui/releases/download/f/xformers-0.0.14.dev0-cp310-cp310-win_amd64.whlcp .\bitsandbytes_windows\*.dll .\venv\Lib\site-packages\bitsandbytes\cp .\bitsandbytes_windows\cextension.py .\venv\Lib\site-packages\bitsandbytes\cextension.pycp .\bitsandbytes_windows\main.py .\venv\Lib\site-packages\bitsandbytes\cuda_setup\main.pyaccelerate config有2g左右的文件需要下载,依赖网速,可能需要半小时。其中最后一步是一个配置文件,按照你的机器选就行了,我的1080是老显卡很多优化没有,所以大部分选的NO。
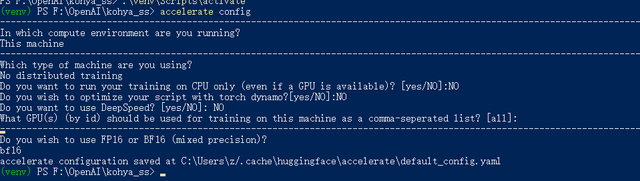
你可以随时更改这个配置,只需要执行下面3个命令重新配置(建议第一次都选NO,后面再看看你的显卡能打开哪些开关加速)
cd kohya_ss
.\venv\Scripts\activate
accelerate config
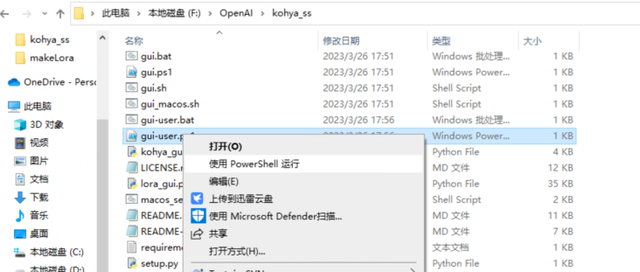
安装好后,会有个kohya_ss目录,大小6g左右。然后右键使用powershell执行gui-user.ps1
就会弹出GUI界面,如下图:(建议你关掉已经启动的Stable Diffusion绘图和其他占用显存的程序,训练需要6G以上的显存空间)
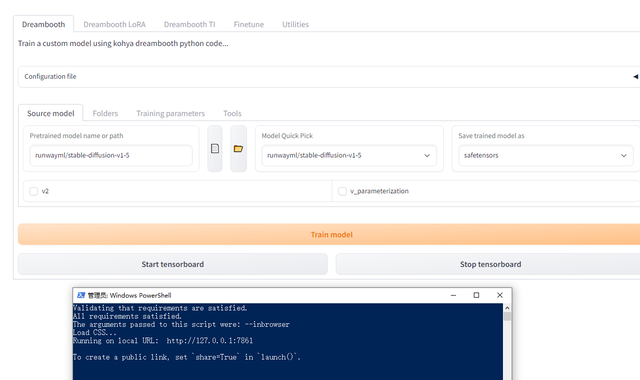
到这里,训练环境就搭建好了。
二。图片处理和标注
1.图片下载处理
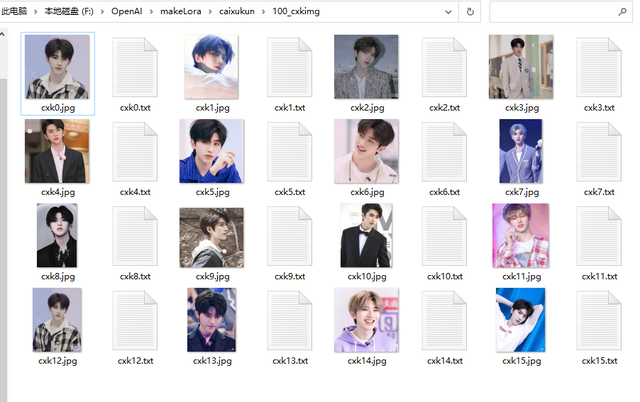
去网上下载蔡徐坤的图片,各种角度的都找,需要清晰的照片,图片分辨率随便,尽量找他单人照。建一个叫100_cxkimg的文件夹,这里100很重要,它是代表进行100次训练,你写50就是50次训练,例如50_annimg,文件名随便,最好不要用中文。你也可以学我用cxk0.jpg到cxk15.jpg命名这16张照片。
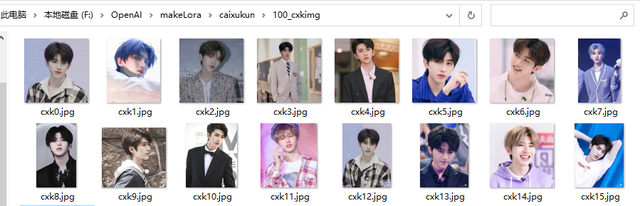
找了16张蔡徐坤的照片
2.标注图片
标注是机器深度学习的重要内容,这里原理不做解释了。标注的越好,模型的泛化就越强。你不标注可能生成就是个没用的模型。标注就是用提示词来说明图片的内容。这里举个例子例如上图cxk4.jpg是个穿西装的蔡徐坤,就标注成:a man in a suit and bow tie。生成标注的办法有多种,例如人工去标注,这里用个简单的办法,让机器自动标注。

BLIP自动标注
科学上网条件下,选择Utilities的BLIP Captioning,填入文件夹名字,点下Caption images,就会生成图片的自动标注。
你也可以手动标注,就是人比较累。图片自动标注后,最好打开每个文件检查下描述的正确性,删掉里面标错的文字,确保模型最后生成更加泛化的模型。

标注就是用提示词描述
一切准备就绪,开始最后一步了,训练模型。
三。训练模型
配置训练参数,选择训练LoRA和基于哪个大模型训练,见下图
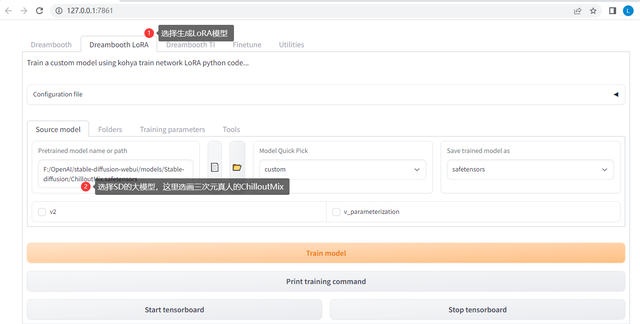
大模型配置
填入训练的目录和输出地址
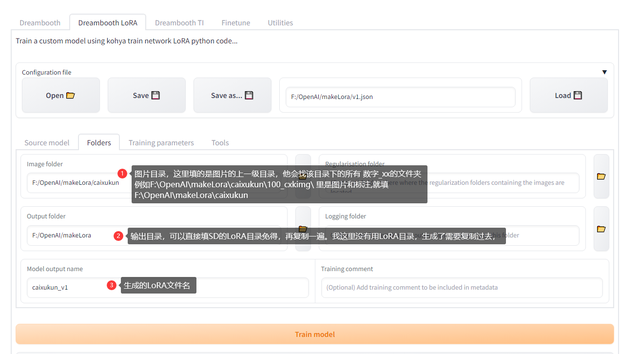
训练目录
训练参数大部分用默认值就行,其他依据你的显卡来填
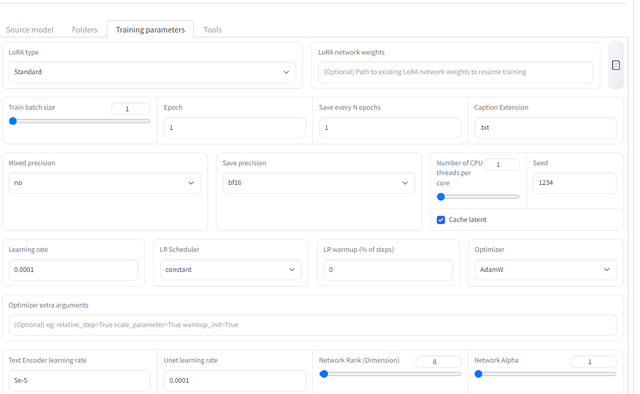
这里有几个重要参数,如果显卡比较老用Mixed precision填no,Save precision填bf16,30系列可以试试fp16。
Learning rate:0.0001
Mixed precision:no
Save precision:bf16
准备就绪就按最下面的训练模型按钮。
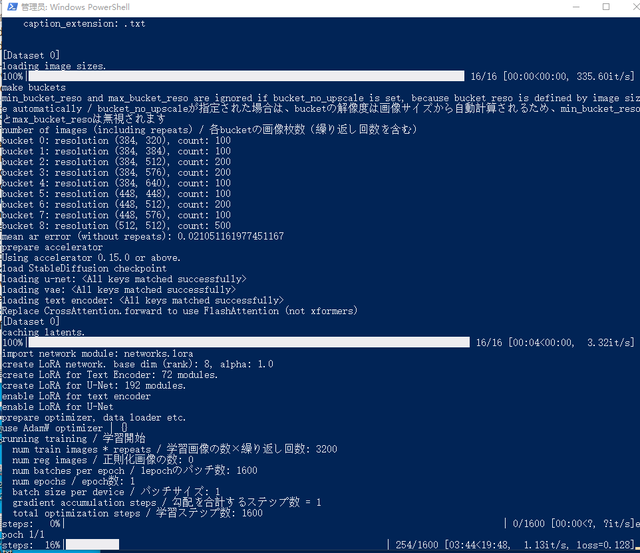
训练模型
1080/8G显卡,16张图片共1600步花了约24分钟训练完成。得到模型caixukun_v1.safetensors。
下面用这个LoRA画的图片:






制作自己喜爱人物的LoRA吧!